Slik får du mest ut av Opus 4.7 i Claude Code

Kort fortalt
Anthropic har sluppet Opus 4.7, sin sterkeste offisielt lanserte modell for koding, bedriftsarbeid og lange agentiske oppgaver (oppgaver der AI-en jobber mot et mål over mange steg). Inne i Claude Code, terminalverktøyet som gjør Claude til en AI-utvikler, har Opus 4.7 nå erstattet Opus 4.6 som standardmodell.
Du kan ikke bare bytte ut modellen og regne med at alt er som før. Opus 4.7 har en ny tokenisator, et nytt standard innsatsnivå og en ny måte å bestemme når den skal tenke på. Prompter og vaner tilpasset Opus 4.6 fungerer fortsatt, men du får ikke det beste ut av den nye modellen uten å justere litt.
Les også:
Hva som faktisk endret seg fra 4.6 til 4.7
Anthropic trekker selv fram to endringer som påvirker hvor mange tokens du bruker. En token er den minste tekstbiten modellen leser — gjerne bare noen få bokstaver, ikke et helt ord. Alt du sender inn og alt modellen svarer med måles i tokens, og tokens er det du betaler for.
Den første endringen er tokenisatoren (engelsk: tokenizer), komponenten som kutter teksten din opp i disse tokensene. Opus 4.7 bruker en ny. Samme setning kan nå gi et annet antall tokens enn den gjorde på Opus 4.6. Dette merker du ikke direkte, men du legger merke til at kostnader og grenser ikke lenger stemmer én-til-én med den gamle modellen.
Den andre endringen handler om tenking. Opus 4.7 tenker mer på høyere innsatsnivåer, spesielt sent i lange sesjoner. Den ekstra tenkingen er grunnen til at kodekvalitet og sammenheng går opp, men det betyr også at tokenbruken øker. En prompt som var billig på 4.6 kan altså bli dyrere på 4.7 om du ikke justerer.
| Hva som endret seg | Hva det betyr for deg |
|---|---|
| Ny tokenisator | Samme tekst, annet antall tokens. Gamle kostnadsestimater stemmer ikke lenger |
| Mer tenking på høy innsats | Bedre resultat, men tokens kan klatre sent i lange sesjoner |
Nytt standard innsatsnivå (xhigh) | Grunnlinjen er satt høyere enn high, så grunnkostnaden ser også annerledes ut enn du er vant med |
| Adaptiv tenking | Tenking er ikke lenger et fast budsjett. Modellen bestemmer steg for steg om den skal tenke |
Strukturer interaktive sesjoner som om du delegerer
Her er tankeskiftet Anthropic vil at du skal gjøre. Se på Claude som en dyktig utvikler du delegerer til, ikke som en kollega du sitter ved siden av og styrer linje for linje.
Hvorfor? Fordi hver gang du svarer med et nytt hint eller en korreksjon, resonnerer Opus 4.7 på nytt før den handler. Mange korte meldingsrunder bygger opp resonneringskostnaden runde for runde. Én velskrevet første melding gjør det ikke.
Anthropic nevner fire konkrete grep:
Spesifiser oppgaven i første melding
Den første meldingen din bør inneholde hensikt (hva du prøver å få til), begrensninger (hva som må eller ikke må skje), akseptkriterier (hvordan du vet at det er ferdig) og hvilke filer det gjelder. En melding som "Skriv om src/auth/login.ts til å bruke den nye SessionProvider, hold eksisterende tester grønne, og ikke endre de offentlige funksjonssignaturene" er verdt ti vage oppfølgingsspørsmål.
Uklare prompter spredt over mange meldingsrunder bruker mer tokens og gir svakere resultater.
Reduser antall brukerrunder
Hver ny melding fra deg starter tenkingen på nytt. Samle spørsmålene dine, gi modellen konteksten den trenger, og la den jobbe videre. Har du tre ting å spørre om, spør om alle i én melding. Vet du allerede hvilke filer det gjelder, lim dem inn.
Bruk auto mode når det passer
Auto mode er en tidlig testversjon (research preview) for Claude Code Max-brukere. Den lar Claude utføre en oppgave uten å stoppe og spørre deg hvert annet steg. Du skrur den på med Shift+Tab.
Den skinner på lange oppgaver der du har gitt full kontekst på forhånd: migreringer, endringer på tvers av filer, kodegjennomganger av en hel tjeneste. Du overleverer planen, går din vei og kommer tilbake til et ferdig resultat.
Be Claude varsle deg når den er ferdig
Et lite triks fra Anthropic-posten: be Claude spille av en lyd når en oppgave er ferdig, så setter den opp et varsel gjennom en hook selv. En hook er et lite skript som utløses av en hendelse, for eksempel Stop. Har du ikke satt opp ~/.claude/settings.json selv, kan du bare be modellen gjøre det for deg.
De fire innsatsnivåene
Innsatsnivået er den viktigste spaken du har. Det styrer hvor hardt modellen prøver på hvert steg — mer innsats gir mer resonnering, flere tokens og som regel bedre svar. Det nye standardnivået er xhigh, et nivå som ikke fantes før Opus 4.7.
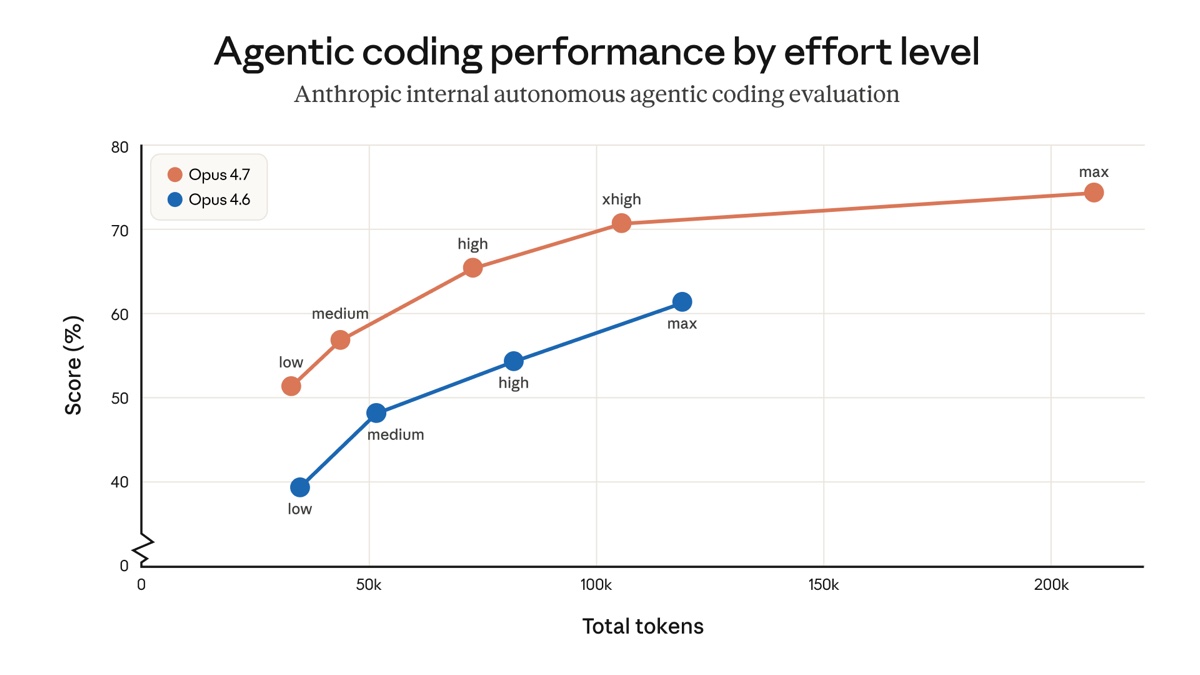
Bilde: Anthropic.
Grafen er det nyttigste sammendraget i posten. På hvert innsatsnivå slår Opus 4.7 Opus 4.6. Selv medium på 4.7 er bedre enn medium på 4.6, noen ganger med færre tokens.
| Nivå | Passer til | Kompromiss |
|---|---|---|
| low / medium | Avgrensede oppgaver, kostnadsbevisst arbeid, raske oppslag | Svakere på harde problemer, men fortsatt foran Opus 4.6 på samme nivå |
| high | Parallelle sesjoner, agentisk arbeid der du vil holde kostnaden nede | Balanse mellom intelligens og pris, bare litt svakere enn xhigh |
| xhigh (standard) | Det meste av koding og agentisk arbeid | Sterk autonomi uten at tokenbruken løper løpsk slik max kan gjøre |
| max | Virkelig tunge problemer, evalueringstesting | Gevinsten blir mindre og mindre, og den kan overtenke enkle steg |
Når du bør bli stående på standard
Anthropics enkle råd er: behold xhigh og se hvor langt den første meldingen din tar deg. Det er gylden middelvei for å designe grensesnitt (API-er) og databasestrukturer, migrere gammel kode, gjennomgå store kodebaser og for det meste av arbeid på tvers av filer.
Når du bør gå under xhigh
Kjører du mange Claude Code-sesjoner parallelt, for eksempel ved å fordele arbeidet over et stort kodelager (en monorepo) eller la agenter jobbe over natten, sparer high tokens uten stort kvalitetstap. For raske filendringer og enkle oppslag holder medium eller low.
Når du bør skru opp til max
Bruk max med vilje. Den hjelper på problemer som faktisk trenger mer resonnering: en vrien bug på tvers av et dusin filer, et kronglete arkitekturspørsmål, eller en testkjøring der du vil se hvor langt modellen strekker seg. Å bruke max som standard er sløseri. Den er mer tilbøyelig til å overtenke enkle steg.
Du kan veksle innsatsnivå midt i en oppgave. Starter du på xhigh og kjører deg fast, skru opp til max for ett steg og gå tilbake etterpå.
Adaptiv tenking erstatter faste tenkebudsjetter
Før Opus 4.7 kunne du sette et fast tenkebudsjett ("bruk opptil 10 000 tenketokens per steg") og modellen prøvde å bruke dem. Opus 4.7 støtter ikke dette lenger. I stedet bestemmer den på hvert steg om den i det hele tatt skal tenke.
Dette heter adaptiv tenking (engelsk: adaptive thinking). Logikken er enkel: et lett spørsmål har ikke nytte av lang resonnering, så modellen bør svare raskt. Et vanskelig steg har nytte av det, så modellen bør tenke mer. Gjennom en agentisk kjøring bygger besparelsene seg opp og svarene føles raskere.
Anthropic sier at Opus 4.7 overtenker merkbart mindre enn tidligere modeller. Dette er hovedgrunnen til at max ikke lenger er den riktige standarden — adaptiv tenking sammen med xhigh tar deg mesteparten av veien uten ekstrakostnaden.
Slik styrer du tenkeraten
Du kan fortsatt påvirke hvor mye modellen tenker, gjennom prompten selv:
- Vil du ha mer tenking? "Tenk nøye og steg for steg før du svarer. Dette problemet er vanskeligere enn det ser ut."
- Vil du ha mindre tenking? "Prioriter å svare raskt framfor å tenke dypt. Er du i tvil, svar direkte."
Positive formuleringer virker bedre enn negative. Det funker bedre å fortelle modellen hva den skal gjøre enn hva den ikke skal gjøre.
Tre standardoppførsler som er endret
Noen innebygde vaner er endret mellom Opus 4.6 og 4.7. Har du finjustert promptene dine for den eldre modellen, er det disse du bør se opp for.
Kortere svar på enkle spørsmål, lengre på åpne
Opus 4.6 var ordrik som standard. Opus 4.7 tilpasser lengden etter oppgavens kompleksitet. Et enlinjes oppslag får et enlinjes svar. En åpen analyse får den dybden den trenger.
Er arbeidsflyten din avhengig av en bestemt lengde eller stil, si det rett ut i prompten. Og gi positive eksempler på stemmen du vil ha, heller enn en liste med "ikke gjør dette". "Skriv et sammendrag på to avsnitt på enkelt norsk" funker bedre enn "ikke vær for kort og ikke vær for formell".
Færre verktøykall, mer resonnering
Opus 4.7 griper sjeldnere etter verktøy. Den leser færre filer, kjører færre søk og bruker mer av innsatsen sin på å tenke. På de fleste oppgaver gir dette bedre resultater: mindre støy, mer signal.
Men hvis oppgaven din faktisk har nytte av aggressiv verktøybruk, for eksempel brede søk i en kodebase eller å lese mange filer for å finne en bug, fortell modellen når og hvorfor den skal bruke verktøyet. Et hint som "søk i kodelageret etter alle steder denne funksjonen brukes før du gjør endringer" gjenoppretter oppførselen du hadde på Opus 4.6.
Færre delagenter som startes automatisk
En delagent (engelsk: subagent) er en egen AI-arbeider hovedsesjonen kan starte for å håndtere en del av oppgaven parallelt. Opus 4.7 er mer tilbakeholden her og starter dem sjeldnere som standard.
Hvis arbeidet ditt naturlig sprer seg utover (gjennomgang av mange filer, uavhengige sjekker), be om oppførselen direkte. Anthropic foreslår denne varianten:
Ikke start en delagent for arbeid du kan fullføre direkte i ett svar (for eksempel å skrive om en funksjon du allerede ser). Start flere delagenter i samme runde når arbeidet fordeler seg på mange oppgaver eller flere filer skal leses.
Uten en slik dytt gjør Opus 4.7 ofte bare jobben selv i én runde. Det er som regel greit, men tregere på oppgaver som faktisk er parallelle.
En helt vanlig tirsdag med Opus 4.7
Hvordan ser alt dette ut sammen? Her er en dag som bruker de nye standardene slik Anthropic foreslår.
| Klokka | Hva som skjer |
|---|---|
| 09:00 | Du åpner Claude Code med standardnivået xhigh. Du endrer ingenting. |
| 09:15 | En migrering. Du skriver én detaljert første melding med hensikt, begrensninger, akseptkriterier og filstier. Claude leser konteksten og starter uten å stille oppfølgingsspørsmål. |
| 10:30 | Raskt oppslag: "hvor ligger Stripe-webhook-handleren?" Du legger til "Prioriter å svare raskt framfor å tenke dypt". Claude svarer med én linje. Ingen bortkastede tenketokens. |
| 11:00 | En vanskeligere bug på tvers av fem filer. Du skrur opp til max for én runde: "Tenk nøye, dette går på tvers av flere moduler". Claude graver seg ned. Etterpå går du tilbake til xhigh. |
| 13:00 | En lang omskriving av hele auth-modulen. Du skrur på auto mode med Shift+Tab, overleverer planen, og går til lunsj. |
| 14:15 | Du er tilbake. Auto mode har fullført omskrivingen, kjørt testene og oppsummert endringene. Du leser gjennom og lagrer endringene (committer). |
| 16:00 | Kodegjennomgang på tvers av tjenesten. Du ber Claude starte delagenter parallelt: "Start delagenter for hver fil i src/payments/. Rapporter tilbake i ett samlet sammendrag." Claude sprer seg utover og kommer tilbake med én rapport. |
| 17:30 | Du ber Claude spille av en lyd når den endelige bygget er ferdig. Den setter opp en Stop-hook selv og avslutter dagen. |
Ingenting av dette krever spesielt oppsett. Det er bare Opus 4.7 med standard innsatsnivå og vanen med å skrive gode første meldinger.
Ordliste
| Begrep | Forklaring |
|---|---|
| Opus 4.7 | Anthropics sterkeste allment tilgjengelige modell, rettet mot koding, bedriftsarbeid og lange agentiske oppgaver |
| Claude Code | Anthropics terminalverktøy som gjør Claude til en AI-utvikler med tilgang til filene, verktøyene og kommandoene dine |
| Token | Den minste tekstbiten en modell leser — gjerne noen få bokstaver lang. Både det du sender inn og det modellen svarer med måles i tokens |
| Tokenisator (tokenizer) | Komponenten som kutter tekst opp i tokens. Opus 4.7 bruker en ny, så samme tekst gir annet antall tokens enn på Opus 4.6 |
| Innsatsnivå (effort level) | En spake som styrer hvor hardt modellen prøver. Nivåene er low → medium → high → xhigh → max |
| xhigh | Et nytt innsatsnivå mellom high og max. Det er standarden for Opus 4.7 i Claude Code |
| Adaptiv tenking (adaptive thinking) | Opus 4.7 sin måte å bestemme, på hvert steg, om tenking hjelper — i stedet for å bruke et fast budsjett |
| Agentisk arbeid (agentic work) | Oppgaver der AI-en jobber mot et mål over mange steg, bruker verktøy og tar egne avgjørelser underveis |
| Delagent (subagent) | En egen AI-arbeider som startes for å håndtere deler av en oppgave parallelt med hovedsesjonen |
| Auto mode | En Claude Code-funksjon som lar modellen utføre en oppgave uten å be om mellomsjekker, skrus på med Shift+Tab |
| Hook | Et lite skript som utløses av en bestemt Claude Code-hendelse, som Stop. Brukes her for å spille av en lyd når oppgaven er ferdig |
Kilder og ressurser
- Best practices for using Claude Opus 4.7 with Claude Code — Anthropic-posten denne artikkelen oppsummerer
- Introducing Claude Opus 4.7 — Lanseringsannonse med full liste over modellendringer
- Auto mode in Claude Code — Bakgrunn på auto mode-forhåndsfunksjonen
- Claude prompting best practices — Anthropics generelle promptguide
- Context and session management in Claude Code — Søsterpost om å håndtere lange Claude Code-sesjoner
- Claude Code documentation — Offisiell referanse for innsatsnivåer, auto mode og oppsett