Best Practices for Using Opus 4.7 in Claude Code

In Brief
Anthropic has released Opus 4.7, its strongest generally available model for coding, enterprise workflows, and long-running agentic work (tasks where the AI works toward a goal over many steps). Inside Claude Code, the terminal tool that turns Claude into an AI developer, Opus 4.7 now replaces Opus 4.6 as the default.
You cannot just swap models and assume everything stays the same. Opus 4.7 has a new tokenizer, a new default effort level, and a new way of deciding when to think. Prompts and habits tuned for Opus 4.6 will still work, but they will not get the best out of the new model.
Related reading:
What actually changed between Opus 4.6 and 4.7
Anthropic's own post flags two changes that shift how many tokens you burn through. A token is the small unit of text the model reads — usually a few letters long, not a full word. Every request and every response is measured in tokens, and tokens are what you pay for.
The first change is the tokenizer (tokenisator), the piece that chops your text into those tokens. Opus 4.7 uses a new one. The same sentence can now produce a different number of tokens than it did on Opus 4.6. This is not something you feel directly. You just notice that costs and limits do not map one-to-one with the old model.
The second change is thinking behaviour. Opus 4.7 tends to think more at higher effort levels, especially on later turns in long sessions. That extra thinking is why coding quality and coherence go up, but it also means tokens go up. So a prompt that was cheap on Opus 4.6 can become more expensive on 4.7 unless you adjust.
| What changed | What it means for you |
|---|---|
| New tokenizer | Same text, different token count. Old cost estimates will drift |
| More thinking at high effort | Better output, but tokens can climb, especially late in long sessions |
New default effort level (xhigh) | The baseline is set higher than high, so first-run costs look different too |
| Adaptive thinking | Thinking is no longer a fixed budget. The model decides step by step when to think |
Structure interactive sessions like you are delegating
Here is the mindset shift Anthropic wants you to make. Treat Claude as a capable engineer you are delegating to, not a pair programmer you are guiding line by line.
Why? Because every time you reply with a new hint or correction, Opus 4.7 reasons again before acting. Many short turns stack up reasoning overhead. One well-specified first turn does not.
Anthropic lists four concrete moves:
Specify the task up front
Your first message should contain intent (what you are trying to do), constraints (what you must or must not do), acceptance criteria (how you will know it is done), and relevant file locations. A message like "Refactor src/auth/login.ts to use the new SessionProvider, keep the existing tests green, and do not change the public function signatures" is worth ten vague follow-up questions.
Ambiguous prompts spread across many turns tend to reduce both token efficiency and output quality.
Reduce the number of user turns
Every user turn restarts the reasoning loop. Batch your questions, hand over the context, and let the model keep moving. If you have three things to ask, ask them in one message. If you already know the file paths, paste them in.
Use auto mode when appropriate
Auto mode is a research-preview feature for Claude Code Max users. It lets Claude execute a task without checking in every few steps. You toggle it on with Shift+Tab.
It shines on long-running tasks where you have provided full context up front: migrations, multi-file refactors, code reviews across a service. You hand over the plan, step away, and come back to a result.
Ask Claude to notify you when it is done
A small trick from the Anthropic post: ask Claude to play a sound when a task completes, and it will set up its own hook-based notification. A hook is a small script that fires on an event like Stop. If you have not wired up ~/.claude/settings.json yourself, you can just ask the model to do it for you.
The four effort levels
Effort level is the single biggest dial you have. It controls how hard the model tries on each step — more effort means more reasoning, more tokens, and usually better answers. The new default is xhigh, a level that did not exist before Opus 4.7.
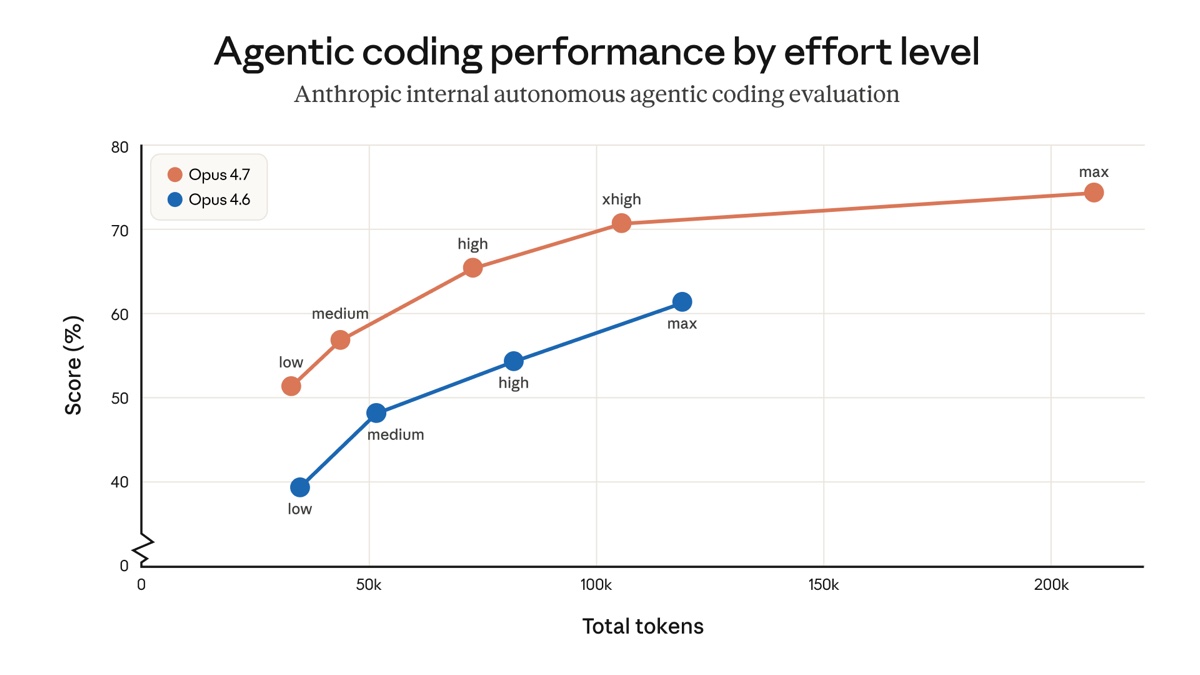
Image: Anthropic.
The chart is the most useful summary in the post. At every effort level, Opus 4.7 beats Opus 4.6. Even medium on 4.7 outperforms medium on 4.6, sometimes with fewer tokens.
| Level | Best for | Trade-off |
|---|---|---|
| low / medium | Tight scopes, cost-sensitive tasks, quick lookups | Weaker on hard problems, but still ahead of Opus 4.6 at the same level |
| high | Concurrent sessions, budget-conscious agentic work | Balanced intelligence and cost, only a small drop from xhigh |
| xhigh (default) | Most coding and agentic work | Strong autonomy without the runaway token use max can produce |
| max | Genuinely hard problems, eval testing | Diminishing returns, can overthink simple steps |
When to stay on the default
Anthropic's plain recommendation is: keep xhigh and see how far your first turn takes you. It is the sweet spot for designing APIs and schemas, migrating legacy code, reviewing large codebases, and most multi-file work.
When to drop below xhigh
If you are running many Claude Code sessions in parallel, say fanning out across a monorepo or letting agents work overnight, high saves tokens without a large quality drop. For quick file edits and simple lookups, medium or low is plenty.
When to push to max
Use max deliberately. It helps on problems that really need more reasoning: a gnarly bug across a dozen files, a cryptic architecture question, or an eval run where you want to test the ceiling. Using max as a default is wasteful. It is more prone to overthinking simple steps.
You can toggle effort during the same task. If you start on xhigh and hit a wall, bump up to max for one step and drop back down.
Adaptive thinking replaces fixed thinking budgets
Before Opus 4.7, you could set a fixed thinking budget ("use up to 10,000 thinking tokens per step") and the model would try to spend them. Opus 4.7 does not support that anymore. Instead, it decides at each step whether to think at all.
This is called adaptive thinking (adaptiv tenking). The idea is simple: an easy question does not benefit from long reasoning, so the model should answer quickly. A hard step does benefit, so the model should think more. Across an agentic run, the savings add up and responses feel faster.
Anthropic says Opus 4.7 overthinks meaningfully less than earlier models. This is the main reason max is no longer the right default — adaptive thinking plus xhigh gets you most of the way without the extra cost.
Nudging the thinking rate
You can still influence how much the model thinks, through the prompt itself:
- Want more thinking? "Think carefully and step-by-step before responding. This problem is harder than it looks."
- Want less thinking? "Prioritise responding quickly rather than thinking deeply. When in doubt, respond directly."
Positive framing works better than negative framing. Telling the model what to do lands better than telling it what not to do.
Three default behaviours that changed
A handful of out-of-the-box habits shifted between Opus 4.6 and 4.7. If your prompts were tuned for the older model, these are the ones to watch.
Shorter answers on simple questions, longer on open-ended ones
Opus 4.6 was default-verbose. Opus 4.7 calibrates length to task complexity. A one-line lookup gets a one-line answer. An open-ended analysis gets the depth it needs.
If your workflow relies on a specific length or style, say so explicitly in the prompt. And give positive examples of the voice you want rather than a list of "don't do this" rules. "Write a two-paragraph summary in plain English" works better than "don't be too short and don't be too formal".
Fewer tool calls, more reasoning
Opus 4.7 reaches for tools less often. It reads fewer files, runs fewer searches, and spends more of its effort on thinking. For most tasks this produces better results: less noise, more signal.
But if your use case actually benefits from aggressive tool use, say searching broadly across a codebase or reading many files to find a bug, tell the model when and why to use the tool. A hint like "search the repo for all callers of this function before making changes" restores the behaviour you had on Opus 4.6.
Fewer subagents spawned automatically
A subagent is a separate AI worker the main session can spawn to handle part of a task in parallel. Opus 4.7 is more judicious here. It spawns them less often by default.
If your work fans out naturally (reviewing many files, running independent checks), ask for the behaviour directly. Anthropic gives this example:
Do not spawn a subagent for work you can complete directly in a single response (e.g., refactoring a function you can already see). Spawn multiple subagents in the same turn when fanning out across items or reading multiple files.
Without that nudge, Opus 4.7 will often just do the work itself in one turn. That is usually fine, but slower on tasks that really are parallel.
A normal Tuesday with Opus 4.7
What does all this look like stitched together? Here is a day that uses the new defaults the way Anthropic suggests.
| Time | What happens |
|---|---|
| 9:00 | You open Claude Code with the default xhigh setting. You do not change anything. |
| 9:15 | A migration task. You write one detailed first turn with intent, constraints, acceptance criteria, and file paths. Claude reads the context and starts working without asking clarifying questions. |
| 10:30 | A quick lookup: "where is the Stripe webhook handler?" You prompt with "Prioritise responding quickly rather than thinking deeply." Claude answers in one short line. No wasted thinking tokens. |
| 11:00 | A harder bug across five files. You bump to max for one turn: "Think carefully, this spans multiple modules." Claude digs in. Afterwards you drop back to xhigh. |
| 13:00 | A long refactor across the whole auth module. You toggle auto mode with Shift+Tab, hand over the plan, and go for lunch. |
| 14:15 | You come back. Auto mode has finished the refactor, run the tests, and summarised the diff. You review and commit. |
| 16:00 | A code review across the service. You ask Claude to spawn subagents in parallel: "Spawn subagents for each file in src/payments/. Report back with findings in one combined summary." Claude fans out, comes back with a single report. |
| 17:30 | You ask Claude to play a sound when the final build finishes. It wires up a Stop hook itself, then closes out the day. |
None of that requires exotic configuration. It is just Opus 4.7 with the default effort level and a habit of writing good first turns.
Glossary
| Term | Definition |
|---|---|
| Opus 4.7 | Anthropic's strongest generally available model, aimed at coding, enterprise workflows, and long-running agentic tasks |
| Claude Code | Anthropic's terminal tool that turns Claude into an AI developer with access to your files, tools, and commands |
| Token | The small unit of text a model reads, usually a few letters long. Input and output are both measured in tokens |
| Tokenizer | The piece that splits text into tokens. Opus 4.7 uses a new one, so the same text produces a different token count than on Opus 4.6 |
| Effort level | A dial that controls how hard the model tries on each step. Levels run low → medium → high → xhigh → max |
| xhigh | A new effort level that sits between high and max. It is the default for Opus 4.7 in Claude Code |
| Adaptive thinking | Opus 4.7's approach of deciding, at each step, whether thinking will help, instead of using a fixed budget |
| Agentic work | Tasks where the AI works toward a goal over many steps, using tools and making decisions on its own |
| Subagent | A separate AI worker spawned to handle part of a task in parallel with the main session |
| Auto mode | A Claude Code feature that lets the model execute a task without asking for check-ins, toggled with Shift+Tab |
| Hook | A small script that fires on a specific Claude Code event, like Stop. Used here to play a sound when a task finishes |
Sources and resources
- Best practices for using Claude Opus 4.7 with Claude Code — The Anthropic post this article summarises
- Introducing Claude Opus 4.7 — Launch announcement with the full list of model changes
- Auto mode in Claude Code — Background on the auto-mode research preview
- Claude prompting best practices — Anthropic's general prompting guide
- Context and session management in Claude Code — Companion post about managing long Claude Code sessions
- Claude Code documentation — Official reference for effort levels, auto mode, and configuration